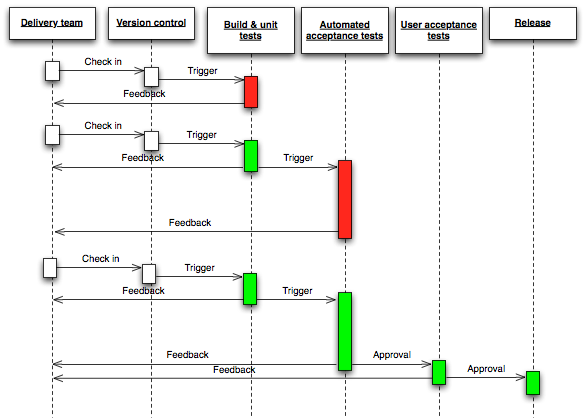
This is continuous of previous post "Continuous deliver - Introduction"
When
we think of Continuous Delivery, mostly we think a lot about the tools
which is important however, the real challenge come because of existing
design of your system specially when it is monolithic architecture,
which slow down the developer and de-motivate them to do re-factoring
for project betterment.
Here are few of many challenge with monolithic architecture
1.
Build: Everything is configure to run under one build task which slow down the build and application start-up time.
2.
Test Case: Test suites tend to grow too large, making the feedback loop slow which is a kind of an enemy instead of a companion.
3.
Single Project for all code: This compound above two problem, also result into less ownership when multi-functional team work on such project.
4.
Management: Hard to manage technical debt.
Here are some step toward resolving those challenges.
Convert the project into multi-module project
Split
the monolithic application into multi-module, you may not be able to
move the source code quickly , however create the module and move the
test cases into respective module should be easier and less risky, then
create the separate jenkins pipeline for each module.
Advantage 1. Each module has its of development pipeline
2. Focused Ownership as each functional team will be responsible for its own module
3. Quick feedback as module specific test cases are executing instead of large test suite
Tools
Gradle: Customize the build script to create the multiple module
project, gradle also has a capability to allow the parallel task
execution
Project Structure
(root)Project\build.gradle
(Module1)Project\Module\Module1\build.gradle
(module2)Project\Module\Module2\build.gradle
Categorize the test cases
Small/Unit test: These are method level unit test case
which
runs in memory and in isolation without any dependency, below are advantage of these test cases
1. They runs real fast, so should be triggered for each commit
2. They are primarily useful for developer to understand the code and
design , it motivate the developer to refector the code as there is
test case to validate it.
3. Helps to collaborate well among the developer
Medium/Component test/ Module level test case, test each component in flow
1. This should also run quickly, important test case should run as a
part of development pipeline, all test case should run as a part of
master pileline (before reaching to QA)
2. No mock for component in flow
3. Mock other modules/external dependency
4. They are primarily useful for business to ensure business test case are green and covered
Large test/Integration test/ Application level test case which test entire flow(excluding external dependency).
1. They are slow in nature, they should run as a part of qa pipeline.
2. No mock for any component in flow
3. Mock or test account for external dependency
4. Primary useful to test the integrity of the system
Source folders
src/test – unit tests
src/test-component – Component tests
src/test-integration – integration tests
practical challenge:
If the existing project does not have enough unit test case and
organization may not invest on unit test case as it does not add any
business value, possible solution could be to convince the management to
invest on component/medium test as it validate the business and reduce
the regression testing effort
Tool Gradle: Use to
categorize the test case, configure each catagory as source folder and
run each test category as separate build step
TestNG: Use testNG to execute the test case in parallel.
Selenium: To run UI/component test
Code coverage
Code
coverage is a way of ensuring that tests are actually testing the code.
It helps ensuring the quality of tests, not the quality of the product
under test.
Why code coverage
Testing by themselves
do not provide enough confidence unless we know that they cover
significant code coverage. Having all tests successful while, for
example, covering only 15% of the code cannot provide enough trust.
In
general code coverage is tie to unit tests but it should be used with
any type of testing including integration/functional/manual testing
Tool
Jacoco: can be used to capture the back-end code coverage, it has two
step first- capture the coverage, second:- decompile the coverage data
and generate the html
Istanbul: can be used to capture the javascript code coverage.
Gradle: gradle has inbuild plug-in support for jacoco
Jacoco can be configured as agent jar to server so that it can capture the data for manual testing as well.
Provision Deployment environment
Use
Docker to provisioning environment which is recreational with every
build, web server (tomcat ect) /db/ selenium hub-node everything should
run inside its own container with linked each other
Advantage 1.Tear down and create the environment with every build, Infrastructure as code.
2.Application is deployed and bootstrap in isolation and in reproducible environment
3.Docker container are version controlled
4.Developer push the image and Jenkins pulls the container in different environment

Pipeline as Code
1.Jenkins is used as CI tool
2.Jobs maintenance is pain
3.programmatic creation of jobs (job ds and, Pipeline plugin)
Tool : Jenkin DSL is groovy based scripting language which support to generate the jenkins job.